Status NTA 7516: hoe staan de leveranciers ervoor?
Sinds mei 2019 moeten leveranciers voldoen aan NTA 7516. In deze blog lees je wie er aan voldoet!

De Algemene Verordening Gegevensbescherming (AVG) is een Europese verordening. Het is hierdoor voor bedrijven verplicht geworden om de beveiliging van het e-mailverkeer nauw in de gaten te houden. De AVG beschermt persoonsgegevens ongeacht de technologie die wordt gebruikt voor het verwerken en opslaan ervan. In alle gevallen zijn persoonsgegevens onderworpen aan de beschermingsvereisten van de AVG.
Je moet ervoor zorgen dat de persoonlijke gegevens van je medewerkers, maar ook van klanten, altijd volledig veilig blijven..
Het korte antwoord is nee. In onze laatste webinar besprak gastspreker Arie van der Deijl van Aareon het belang van productiegegevens en GDPR-compliance. De AVG is van toepassing op alle organisaties die met gevoelige gegevens te maken hebben, ongeacht of dit persoonsgegevens, productiegegevens of beide zijn. Wanneer productiegegevens worden gedupliceerd naar een testomgeving in 'non-production', moeten organisaties ervoor zorgen dat deze gegevens veilig zijn, terwijl ze hun interne processen en efficiëntie verbeteren.
Een organisatie kan beargumenteren dat hun algemene voorwaarden stellen dat ze gegevens alleen voor testdoeleinden gebruiken. Dit betekent niet dat deze gegevens zomaar gebruikt mogen worden. Volgens de AVG moet alles wat onder persoonsgegevens valt, beschermd worden.
Persoonlijke gegevens zijn alle gegevens die betrekking hebben op een identificeerbaar, levend persoon. Verschillende soorten gegevens die herleidbaar zijn naar een persoon, zijn ook persoonsgegevens. Denk hierbij aan namen, achternamen en huisadressen.
Persoonlijke gegevens die zijn geanonimiseerd, versleuteld of "gepseudonimiseerd", kunnen worden gebruikt om een persoon opnieuw te identificeren. Deze blijven persoonlijke gegevens en vallen onder de AVG. Dit terwijl persoonsgegevens die zodanig zijn geanonimiseerd dat de persoon niet (meer) identificeerbaar is, niet langer als persoonsgegevens worden beschouwd. Om gegevens echt als geanonimiseerd te beschouwen in overeenstemming met de AVG, moet de anonimisering onomkeerbaar zijn.
Om gegevens te kunnen gebruiken bij testen of trainingen, moeten ze eerst volledig geanonimiseerd worden totdat ze onomkeerbaar zijn. Dit staat bekend als "Data Obfuscation" (DO). Dit is een vorm van datamaskering waarbij gegevens opzettelijk worden gecodeerd om ongeautoriseerde toegang te voorkomen. Deze vorm van versleuteling verandert tekst in data naar onbegrijpelijke symbolen zodat de tekst onleesbaar wordt. Maskeren is de belangrijkste manier om gegevens te verduisteren.
Datamaskering is een belangrijke techniek om een structuur te ontwikkelen die lijkt op de huidige, maar heeft een niet-authentieke update van de bedrijfsinformatie die om meerdere redenen kan worden gebruikt, zoals gebruikerstraining en softwaretests. Het belangrijkste doel is om de originele gegevens op te slaan door een operationeel alternatief te hebben voor verschillende situaties waarin de echte gegevens niet nodig zijn..
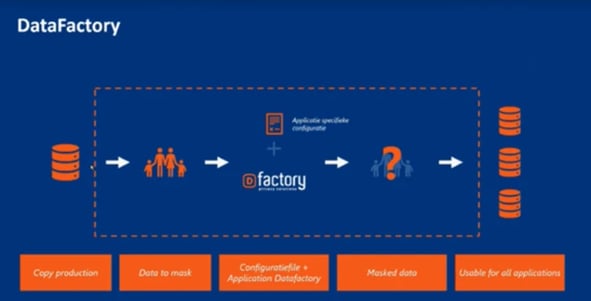
Bron: presentatie van Arie van der Deijl, Aareon.
Er is veel datamaskersoftware ontwikkeld om organisaties te helpen aan regelgevingen te voldoen. Daarbij worden de eigen werkprocessen continu verbeterd. Datamaskering kan op een aantal manieren worden uitgevoerd, waarbij elke methode het best op een bepaald datateypte kan worden toegepast.
We hebben hieronder een lijst samengesteld met de verschillende methoden inclusief sterke en zwakke punten:
Het naleven van oude en nieuwe regelgevingen veroorzaakt nog steeds veel problemen binnen organisaties. Veel organisaties zijn niet op de hoogte van datawetten, waardoor ze in hun huidige processen een groot risico lopen op boetes.
Smartlockr neemt deze zorg weg door je volledig te ontzorgen, zodat jij je als organisatie kan concentreren op waar je goed in bent: je core business.
Wil je meer weten over de AVG?


Sinds mei 2019 moeten leveranciers voldoen aan NTA 7516. In deze blog lees je wie er aan voldoet!
Wat houdt de NTA 7516 precies in? Gemeenten, zorgorganisaties en de juridische sector moeten aan deze norm voldoen. Deze blog maakt het makkelijk...